Use Audio with your LLMs!
Capturing Non-Text Information and Richer Context with LLMs

Anish Palakurthi
LinkedInGone are the days of passing your audio files into Whisper, waiting for the output, then finally sending it to an LLM — say hello to Audio Inputs, a new data type supported by BAML for your LLM workflows!
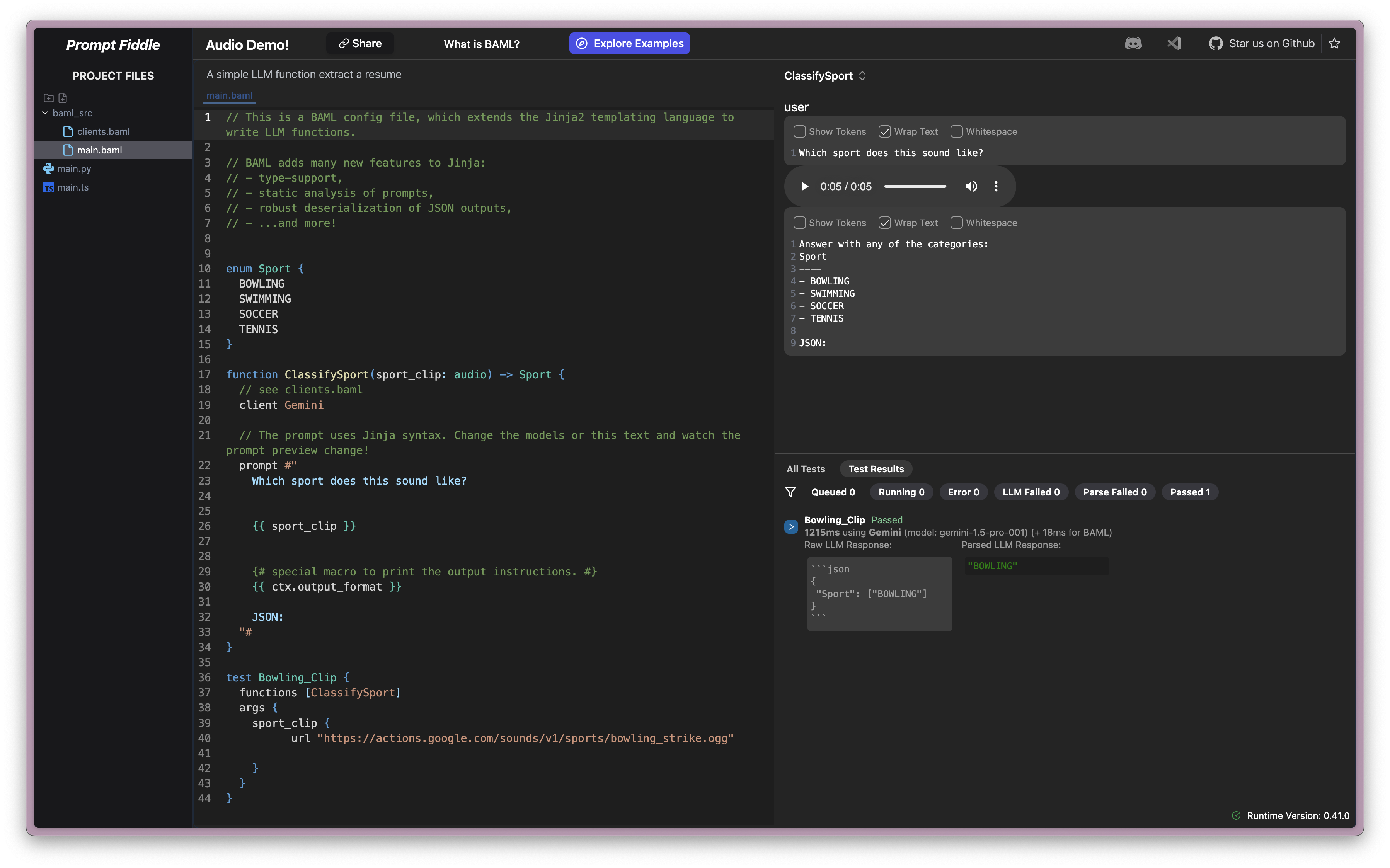
Recent models such as Gemini's 1.5 Pro and Flash support a wide variety of multimodal input, including raw audio files such as mp4, wav, ogg, and more. All of these formats are supported by BAML!
Unlike other models, which transcribe audio to text before querying, Gemini 1.5 Pro and Flash use a single model trained end-to-end across text, vision, and audio. The same neural network processes all inputs and outputs, allowing the model to capture more information from the audio, including tone, multiple speakers, and background noise!
At present, Gemini is the only audio input provider. However, as soon as other providers start to roll out these capabilities (GPT-4o audio, wya? ), BAML will immediately support them.
This update adds another BAML benefit to your LLM pipelines -- some providers like Gemini and Anthropic do not support uploading files by public URL and require Base64 input. BAML now abstracts this conversion from your pipelines, allowing you to make requests to any model with URL-based media input and swap between models quickly in your testing.
How to get started:
- Configure a client with audio capabilities using PromptFiddle or our VSCode extension with BAML.
- Pass in your data!
- Test your audio snippet live in the playground!