Build RAG with citations in NextJS (with streaming!)
How to do RAG with NextJS streaming AI APIs

Aaron Villalpando
LinkedInThis article will walk you through implementing RAG with citations in NextJS using
- Structured outputs from LLMs
- Streaming APIs, to get partial results from the AI as they are generated
- ShadCN UI components.
The final example looks like this:
The source code is available on Github
Try out the live demo here
This project uses BAML, our prompt configuration language that extends Jinja to help you get structured outputs from LLMs. BAML can autogenerate a fully typed TypeScript client that can call our prompt templates, handle all deserialization, and stream the results. More on this below!
1: Create a NextJS app with the AI package
npx create-next-app@latest-
npm install ai
2. Initialize BAML
We will use the BAML prompt templating configuration to build our RAG prompt.
npm install @boundaryml/bamlnpx baml-cli init- this will create a directory to place .baml files in.- Get the VSCode extension for BAML syntax highlighting and playground capabilities.
You will also need to adjust your nextjs.config to support native node modules. See this nextjs.config example.
2. Build a prompt
In BAML you build prompts using a schema-first approach. What's this mean? Well, prompt templates are basically functions that take in input variables and return structured outputs. In BAML you literally define your function signatures and then write the prompt using that signature, which helps reduce prompt engineering.
In this RAG example need a function that takes in a question and a list of documents, and outputs an Answer object, with citations, so this is the function we will build:
function AnswerQuestion(question: string, context: Context) -> Answer
Define your input variables
Lets declare the Context input type in a .baml file in the project, which contains the documents the AI will use to answer the question:
class Context {
documents Document[]
}
class Document {
title string
text string
link string
}
Define the Answer schema
The output schema is an Answer object that contains a list of citatons.
When humans write a paper, they usually cite other papers and then write out their answer using those citations. We will make the LLM do the same:
- First give us the citations from the documents that answer the question
- Then give us the answer
This will help reduce hallucinations since the LLM will be more likely to use the generated citations in the answer. You can change this order if you want to experiment with different approaches.
Here's the answer schema, which you can add to any .baml file in your project:
class Answer {
// note this is first in the answer schema -- the LLM will need to gather citations first!
answersInText Citation[]
answer string @description(#"
When you answer, ensure to add citations from the documents in the CONTEXT with a number that corresponds to the answersInText array.
"#)
}
class Citation {
documentTitle string
sourceLink string
relevantTextFromDocument string
number int @description(#"
the index in this array
"#)
}
Now we have the full function signature types! Let's build the prompt.
Build the LLM function
Here's the full function syntax in BAML -- which will get translated into a python or typescript function.
BAML prompts use the Jinja templating language to help you write structured prompts. You can use Jinja to loop over lists, conditionally render parts of the prompt, and more. We added a couple of helper functions to Jinja, explained below.
function AnswerQuestion(question: string, context: Context) -> Answer {
client GPT4 // you can use anthropic, openai, ollama, and others. See the BAML documentation for more.
prompt #"
Answer the following question using the given context below.
CONTEXT:
{% for document in context.documents %}
----
DOCUMENT TITLE: {{ document.title }}
{{ document.text }}
DOCUMENT LINK: {{ document.link }}
----
{% endfor %}
{{ ctx.output_format }}
{{ _.role("user") }}
QUESTION: {{ question }}
ANSWER:
"#
}
There are 2 predefined BAML macros -- ctx.output_format and _.role("user") -- to help us write the output schema instructions into the prompt, and mark a specific part of the prompt as a "user" message.
The {{ ctx.output_format }} line will be replaced with the output structure instructions at runtime, which uses your @description annotations to make things clearer to the LLM.
Answer using this JSON schema format:
{
answersInText: [
{
documentTitle: string,
sourceLink: string,
relevantTextFromDocument: string,
// the index in this array
number: int,
}
],
// When you answer, ensure to add citations from the documents in the CONTEXT with a number that corresponds to the answersInText array.
answer: string,
}
BAML uses type definitions in prompts, which are 4x less costly than JSON Schema.
If you use the BAML Playground in VSCode you can see it rendered in real-time, so you don't have to guess what string will be sent to the LLM client at runtime:
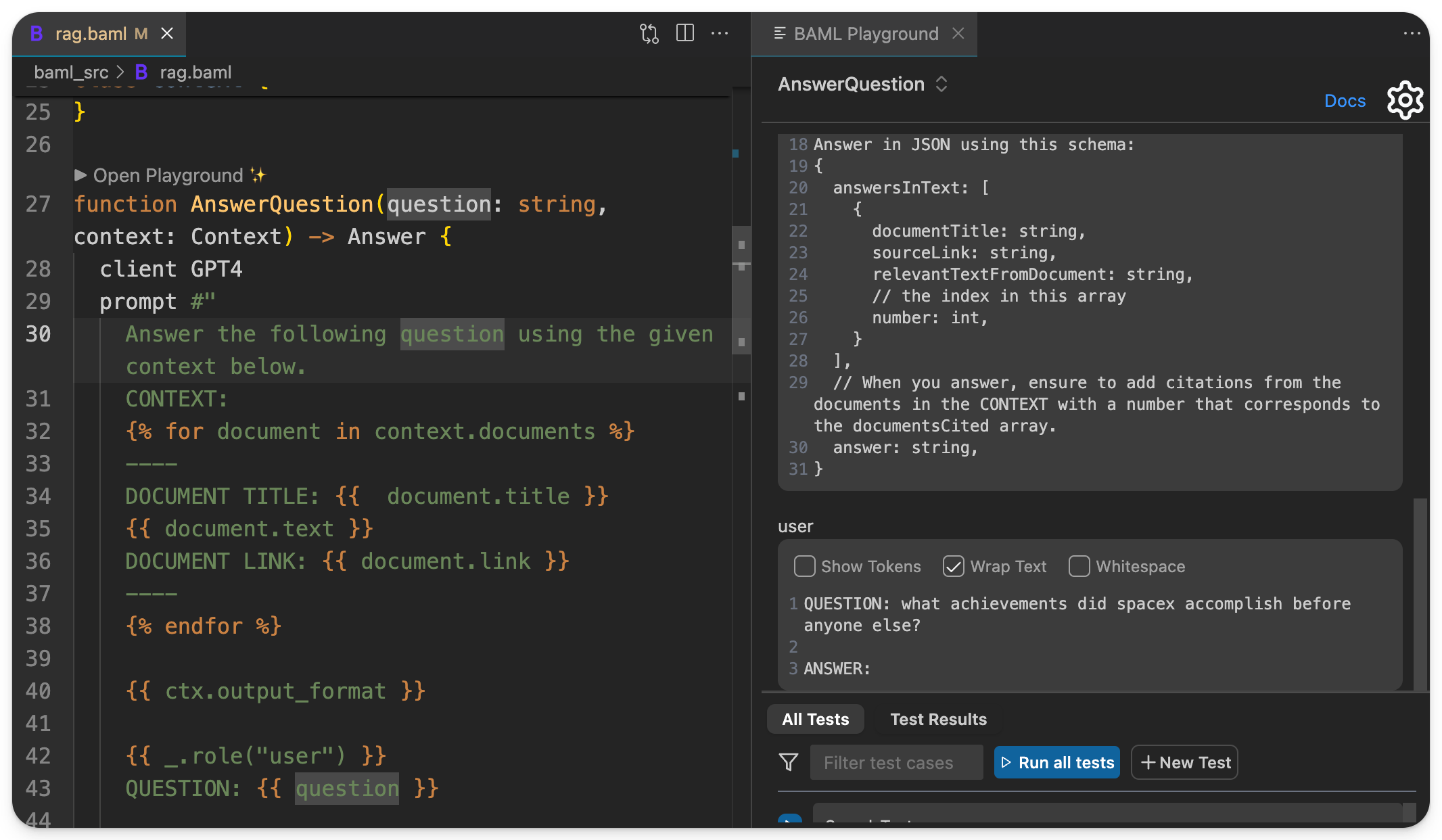
Call your function in NextJS
When you save a .baml file, the BAML VSCode extension generates a typescript client to call the function. Everything runs in your own machine.
Let's build a server action that calls our generated BAML function in a streaming manner. We will use NextJs' createStreamableValue function to stream the results.
Define server action
"use server";
import { createStreamableValue } from "ai/rsc";
import { Answer, b, BookAnalysis, Resume } from "@/baml_client"; // autogenerated by BAML
import { documents } from "@/lib/rag-docs"; // a list of documents we hardcoded
export async function answerQuestion(question: string) {
const answerStream = createStreamableValue<Partial<Answer>, any>();
(async () => {
// Call our BAML function! With full type inference
const stream = b.stream.AnswerQuestion(question, {
documents: documents,
});
// each event is a Partial<Answer>, which means each field in the object may be optional.
for await (const answer of stream) {
if (answer) {
answerStream.update(answer);
}
}
answerStream.done();
})();
return { object: answerStream.value };
}
Consume the stream in a React component
We will add a new page to our NextJS app under app/examples/rag/page.tsx. This page will have a text input for the question, and a button to submit the question to the AI. The answer will be displayed in a textarea, and the citations will be displayed in a list.
This example uses ShadCN UI components, but you can use any UI library you like.
"use client";
import { answerQuestion } from "@/app/actions/streamable_objects";
import { Answer, BookAnalysis } from "@/baml_client";
import { Button, buttonVariants } from "@/components/ui/button";
import { Input } from "@/components/ui/input";
import { Textarea } from "@/components/ui/textarea";
import { sortJsonRecursive } from "@/lib/utils";
import { readStreamableValue } from "ai/rsc";
import Link from "next/link";
import { useState } from "react";
import { ClipLoader } from "react-spinners";
export default function Home() {
const [text, setText] =
useState(`What achievements did spacex accomplish before anyone else?
`);
const [answer, setAnswer] = useState<Partial<Answer> | undefined>(undefined);
const [isLoading, setIsLoading] = useState(false);
const [showRaw, setShowRaw] = useState(false);
return (
<>
<div className="mx-12 flex flex-col items-center w-full py-8">
<div className="max-w-[800px] flex flex-col items-center gap-y-4">
<div className="font-semibold text-3xl">RAG Example</div>
<div className="">
Ask a question to the AI about this{" "}
<Link
className="text-primary-baml hover:underline"
href={"https://en.wikipedia.org/wiki/SpaceX"}
>
SpaceX
</Link>{" "}
wikpedia article to see how RAG works!
</div>
<div className="w-full flex flex-col mt-18 border-border bg-muted rounded-md border-[1px] p-4 items-center">
<div className="font-semibold w-full text-left pl-1">Question</div>
<Input
className="w-[600px]"
value={text}
onChange={(e) => setText(e.target.value)}
/>
<Button
disabled={isLoading}
onClick={async () => {
const { object } = await answerQuestion(text);
setIsLoading(true);
for await (const partialObject of readStreamableValue(object)) {
setAnswer(partialObject);
}
setIsLoading(false);
}}
className="w-fit flex mt-2"
>
Submit
</Button>
</div>
</div>
</div>
</>
);
}
Note that for the purpose of this tutorial we are not addressing how to do document chunking, or doing similarity search. We are just using a hardcoded list of documents:
export const documents: Document[] = [
{
title: "SpaceX Overview",
link: "https://en.wikipedia.org/wiki/SpaceX",
text: `
.... the actual document chunk here
`
}
]
Render the answer and citations
export default function Home() {
// rest of the code here.
return (
{/* the rest of the component up top here */}
<div className="flex flex-col gap-y-4">
<div className="font-semibold flex flex-row text-lg gap-x-1">
<div>Answer</div>
<span>
{isLoading && (
<div className="">
<ClipLoader color="gray" size={12} />
</div>
)}
</span>
</div>
<Textarea
className="w-[600px] h-[120px]"
value={answer?.answer}
readOnly
draggable={false}
contentEditable={false}
/>
<div>
<div className="flex flex-col w-full">
<span className="font-semibold">Citations</span>{" "}
<div className="border-border border-[1px] p-2 text-xs rounded-md min-h-[100px] max-w-[600px]">
{answer?.answersInText?.map((answer, index) => (
<span
key={index}
className="whitespace-pre-wrap break-words"
>
<span className="font-semibold">[{answer.number}]</span>{" "}
{answer.relevantTextFromDocument}
{/* links can cause exceptions if the link is incomplete, so we render it at the end */}
{!isLoading && (
<Link
href={answer.sourceLink ?? "/"}
className="text-primary-baml"
>
{answer.documentTitle}
</Link>
)}
</span>
))}
</div>
</div>
</div>
<div className="">
<div className="font-semibold">Parsed JSON from LLM response</div>
<Textarea
className="w-[600px] h-[160px] mt-4"
value={JSON.stringify(sortJsonRecursive(answer), null, 2) ?? ""}
readOnly
draggable={false}
contentEditable={false}
/>
</div>
</div>
)
)
}
And you're done!
You should now be able to stream responses. Feel free to change the prompt according to your needs. The VSCode BAML playground makes it very easy to test your prompt on various test cases without having to run the whole program.
With BAML we were able to just call a function without worrying about
- Retries, redundancy
- Deserialization (BAML fixes common llm json mistakes as well like missing quotes)
- Streaming partial json objects
and as we were prompt engineering using our types, we always got to see the full prompt.
The full source code is available on Github, along with some more examples.
You can check out the BAML Documentation for more examples, and join our Discord if you have any questions or need help!