Semantic Streaming vs Token-based Streaming
A new technique for streaming structured output from LLMs

Aaron Villalpando
LinkedInSemantic streaming allows you to stream meaningful chunks of data that make more sense for your application, versus streaming tokens. Scroll down to see the interactive example.
Many LLM providers allow us to stream the tokens back from the LLM as they are being generated. This can be really nice! Imagine asking ChatGPT to produce the digits of Pi. The LLM streams different tokens, e.g. 3, ., 14, and we can accumulate them as they come in to build up the final result:
> Please produce Pi to 100 decimal pointsss
LLM Accumulated Streamed Response:
3
3.1
3.14
3.141
Streaming the result adds more precision to the right of the decimal point as more tokens stream in.
However, something more sinister happens if we focus on the left of a decimal point:
> How many tablespoons of water are there in all of Earth's oceans?
Accumulated Streamed Response:
5
53
530
53000
The meaning is completely lost at different points in the stream -- these numbers are orders of magnitude off.
Here's what happens when you plot this as they come in:
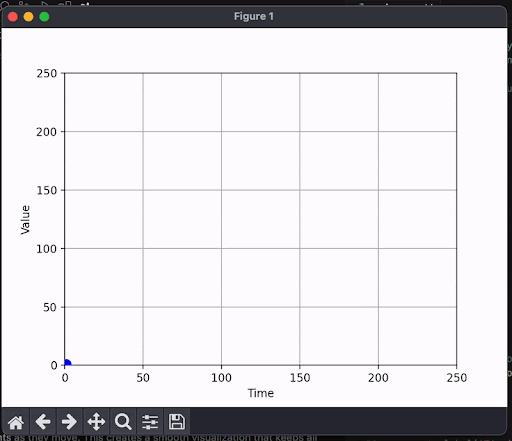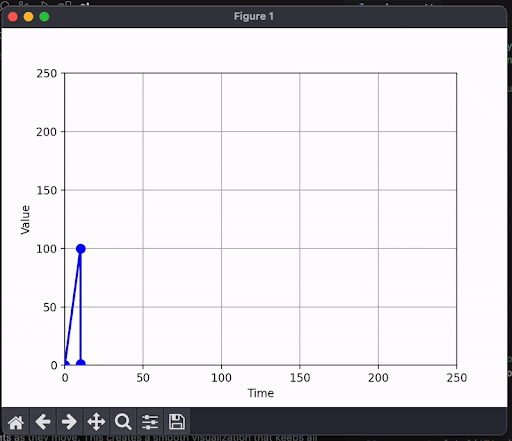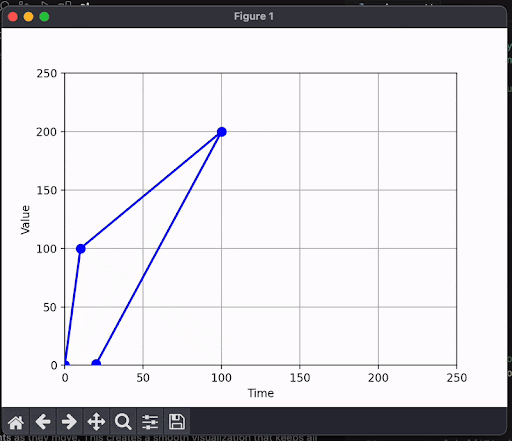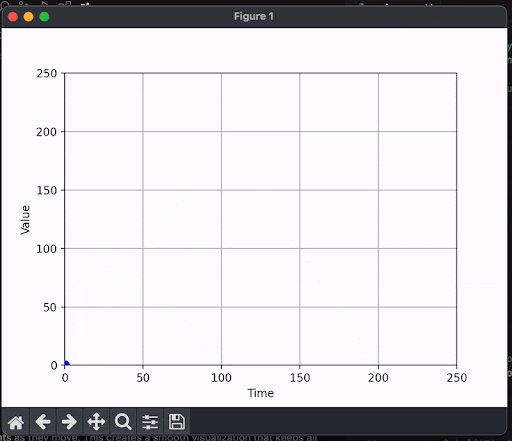
Each datapoint moves along the x axis as more tokens come in. A token does not have the same meaning as "a number in the graph", and so we end up with clunky results.
The Importance of Semantic Streaming
The difference between these two cases illustrates a broader concept - the distinction between token-based streaming and semantic streaming. In these examples, tokens were being streamed, and in one case, the semantics were preserved (the number got more precise with time), while in the other case, the semantics weren't (the number continued to change wildly).
Ultimately, this can lead to poor or even faulty user experience.
Let's think back to the first example again. What if we ask the LLM:
> Which version of my software first introduced new feature X?
3
3.1
3.14
3.141
These numbers are very distinct entities and the introduction of a new feature probably only appears in one of the changelogs. So even though streaming out 3.141 in the context of Pi makes sense, streaming out 3.141 in the context of version numbers makes less sense.
Remember the jarring visual from the dynamically generated graph earlier? That was from token-based streaming. Semantic streaming will enable users of our AI application to see more meaningful results at each step of the stream. Here's what happens when we only render numbers that are fully formed:
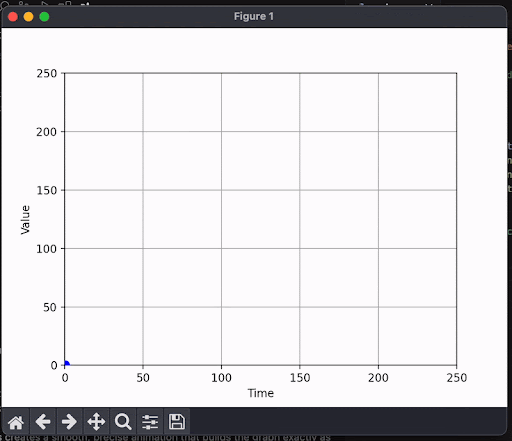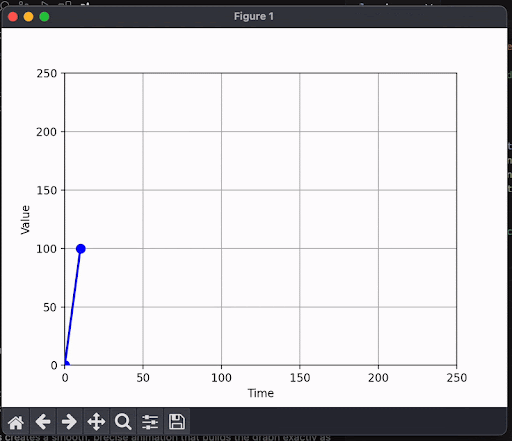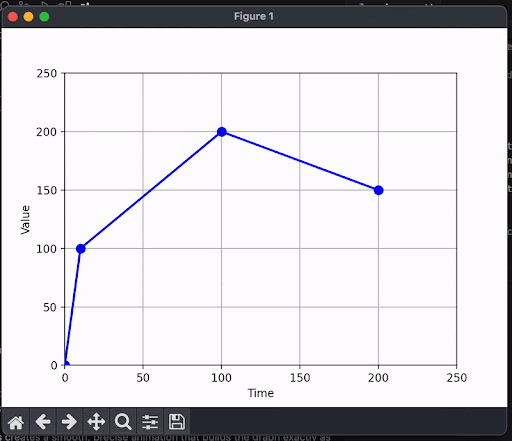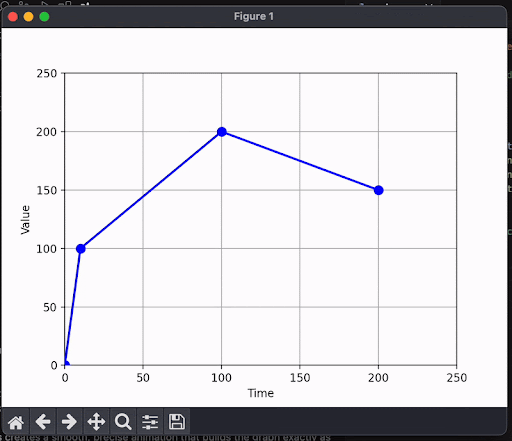
and another example:
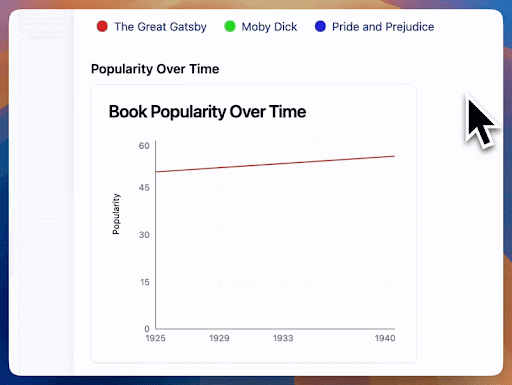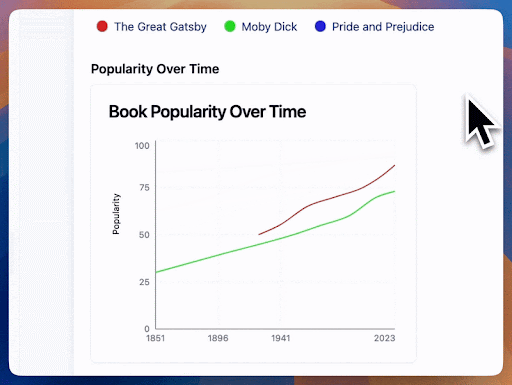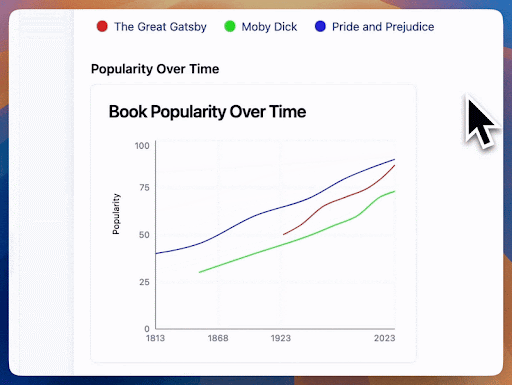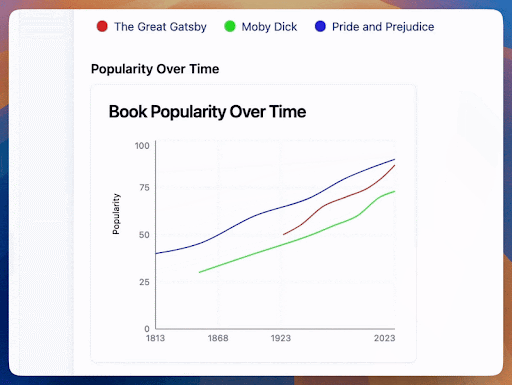
(Try this example here)
Semantic Streaming for any Structured data
You can apply this technique to more than just numbers.
In the example below, we stream a list of Cards, and we only do so when the entire Card is fully formed.
(From @nicoalbanese10)
The UI renders less, and it feels less noisy and jarring for a user.
Here's another example, where we stream the Ingredient quantities as whole numbers, and render each one at a time as it comes in, which allows us to adjust the recipe in real-time as it streams:
You can see how we could reduce noise even further by waiting to show the whole ingredient until both the unit and name are completed.
Semantic Streaming in BAML
We're excited to see new patterns emerge for how to render LLM-generated content in a way that feels more natural. To make this easier on developers we added semantic streaming to BAML -- with support for numbers (lists are coming soon). All numbers in BAML are only streamed when they are complete. No need to do anything else in your code.
You can try the interactive example below:
We'll be supporting more streaming capabilities to the BAML SDKs in the coming months. Stay tuned!