Prompting vs JSON Mode vs Function Calling vs Constrained Generation vs SAP
A technical explanation of every way to extract structed data from an LLM

Vaibhav Gupta
Structured generation is the idea of coercing the LLM to generate some data that you can parse into a data model and then programatically use.
The most common way to extract structured data / do function calling out of an LLM is to somehow get the LLM to output JSON, and then call JSON.parse.
However, there is no reason to assume that JSON, the prevalant serialization for Web APIs, should be the ideal serialization for LLMs. Given the stochastic nature of LLMs, it might even be true that all strict serialization formats are suboptimal, since a single error can cause the entire serialization to be invalid.
In this article, we'll:
- Explain how every current technique of structured data extraction works
- Discuss the pros and cons of each technique
- Introduce a new technique, SAP (Schema-Aligned Parsing), that achieves state-of-the-art accuracy on the Berkeley Function Calling Leaderboard (Jump to SAP)
Problem Space
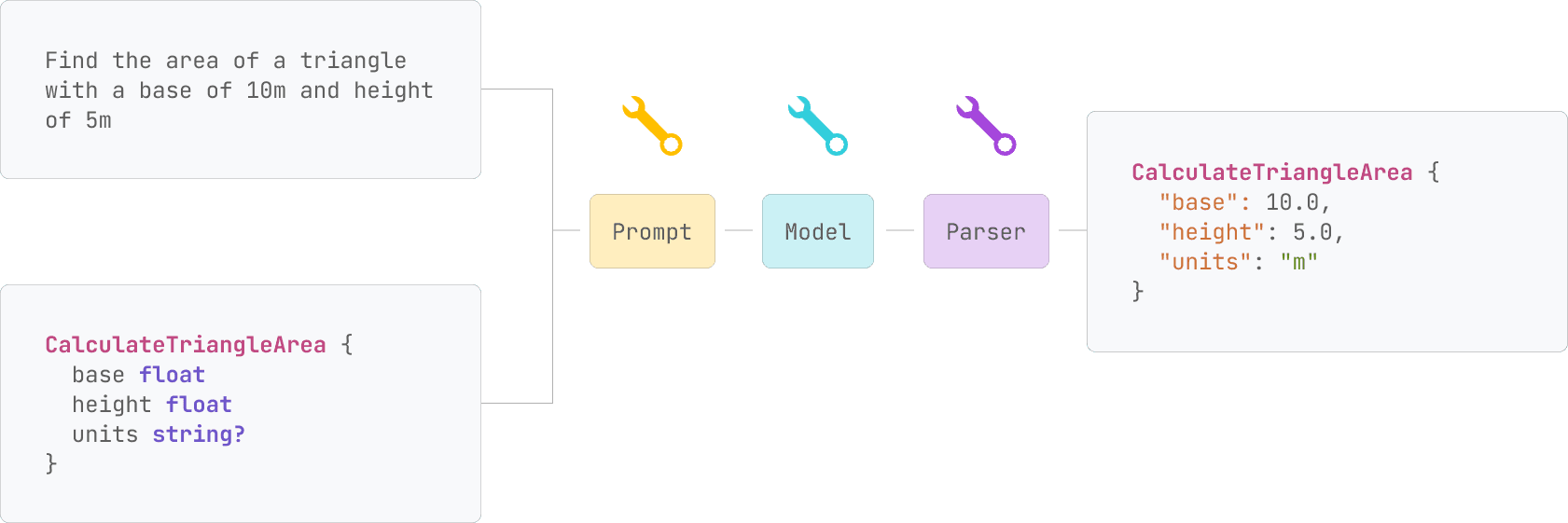
 Change how we construct the prompt and render the schema
Change how we construct the prompt and render the schema Change how tokens are generated
Change how tokens are generated Change how we parse the output of the model into our desired structure
Change how we parse the output of the model into our desired structureAll 9 Techniques
| Category | Technique |
|---|---|
| Prompt | Naive Approach Prompt Engineering Prompt Engineering + Parsing |
| Model | JSON Mode Constrained Generation Function Calling |
| Parser | LLM Retries AST Parsing SAP |
Technique Comparison
We ran the most popular techniques on the Berkeley Function Calling Leaderboard dataset. Here are the results:
| Model | Function Calling | Python AST Parser | SAP |
|---|---|---|---|
| gpt-3.5-turbo | 87.5% | 75.8% | 92% |
| gpt-4o | 87.4% | 82.1% | 93% |
| claude-3-haiku | 57.3% | 82.6% | 91.7% |
| gpt-4o-mini | 19.8% | 51.8% | 92.4% |
| claude-3-5-sonnet | 78.1% | 93.8% | 94.4% |
| llama-3.17b | - | 60.9% | 76.8% |
Technique Breakdown
JSON.parse(..) on the response


Complete Propmt
Generate a resume in JSON format based on the SCHEMA defined below:
{
type: "object",
properties: {
name: {
type: "string",
required: true,
},
contact: {
type: "object",
properties: {
email: {
type: "string",
required: true,
},
phone: {
type: "string",
required: false,
}
},
required: true,
},
education: {
type: "array",
items: {
type: "object",
properties: {
institution: {
type: "string",
required: true,
},
degree: {
type: "string",
required: true,
},
year: {
type: "string",
required: true,
}
}
},
required: true,
},
experience: {
type: "array",
items: {
type: "object",
properties: {
company: {
type: "string",
required: true,
},
role: {
type: "string",
required: true,
},
duration: {
type: "string",
required: true,
}
}
},
required: true,
},
skills: {
type: "array",
items: {
type: "string"
},
required: true,
}
}
}



JSON.parse conditionally.


{ "key", the LLM must choose a token that starts with : to ensure valid JSON.


- JSON is too rigid to use techniques which benefit from verbosity like Chain-of-Thought or Reasoning (See CoT paper which had +40% in accuracy in some datasets)
- JSON is not sufficiently strict.
{ "foo": 1 }is valid JSON, but if you wanted{ "foo": int[] }, it would be close, but still wrong. - The error rate is often 10%+ when compared on larger datasets (see BFCL).
- And most importantly, not every model supports this
Take a grammar restriction:
[0-9]{1,2}\.[0-9]{0,2} - a regular expression that matches numbers with one or two digits before the decimal point and zero to two digits after the decimal point.We first only allow the LLM to pick tokens that match numbers.
After say,
83, the LLM would be forced to pick tokens that started with ..


// Example grammar for a "simple" calculator
?start: expression
?expression: term (("+" | "-") term)*
?term: factor (("*" | "/") factor)*
?factor: NUMBER
| "-" factor
| "(" expression ")"
%import common.NUMBER
Answer
I have no idea tbh...The idea here is to fine-tune the model to intelligently trigger when to use JSON mode.
Example Generation:
- Teach the model a new special token
USE_TOOL. - Whenever the model generates the
USE_TOOLtoken, switch to JSON mode for all subsequent tokens. - Once the JSON is complete (detect this programatically, not by the model), allow the model to pick from all tokens, including
USE_TOOL. - Loop until the model emits the
END_TOKENtoken.



USE_TOOL token, it was not previously supported by all providers. As it is more common, and the interface is becoming more standardized, I've warmed up to it. However, I still have a few reservations:- Function calling suffers from the same schema inaccuracy JSON mode does.
{ "foo": 1 }is valid JSON, but if you wanted{ "foo": int[] }, it would be close, but still wrong. - Most APIs rely on a JSON schema, which is incredibly wasteful in the token space.
- A lot of models still don't support it
- Models that do support it often have degraded accuracy with function calling when compared to just prompting based techniques.

Today, many libraries are treating an LLM like a hammer and throwing every problem its way.
JSON.parse failed due to including a comment? a trailing comma? Ask the LLM to fix the error and try parsing again.This adds unbounded latency and costs to the system. LLMs are already slow and expensive (albiet getting cheaper and faster, but still significantly slower than most software).
Where I see potential, however, is in more complex systems to fix logical inconsistencies. An LLM is likely the only approach for doing this at scale. For example, fixing a scenario where age was off by 3 years.
// Data model
class Person {
name string
job string
birth_year int
age int @assert(
this == now().year - birth_year,
"{this} doesn't match {birth_year} given {now().year}"
)
}
// To fix it, instead of giving the LLM everything (the entire data model), just give it the error and only the properties that are relevant to age.
{
"error": "age=30 doesn't match birth_year=1990 given now.year=2024",
"birth_year": 1990,
"age": 30
}
Current approaches, would likely just retry the entire model, but a more sophisticated approach would be to only give the LLM the error and the relevant properties, reducing costs and latencies. This would be a much more efficient approach, but would require a lot of engineering (and compilers) to get right.[GetTriangleArea(base=5, height=10)] (Note, that this is valid python syntax)
After python_to_json: { "GetTriangleArea": {"base": 5, "base": 10} }


This was one of the few ideas I've seen which step away from JSON, XML, and other similar formats and tries to reframe the problem in a way the LLM may better understand. The issue with generating code, is that code, like JSON, is still a very strict grammar. While code has very few superfluous tokens (like
: or " in JSON), you still rely on a parser you often don't own (the syntax parser of the language). If the LLM, by accident, emits the wrong amount of whitespace, it can completely change what the python parser reads the output.


| Model | Function Calling | Python AST Parser | SAP |
|---|---|---|---|
| gpt-3.5-turbo | 87.5% | 75.8% | 92% |
| gpt-4o | 87.4% | 82.1% | 93% |
| claude-3-haiku | 57.3% | 82.6% | 91.7% |
| gpt-4o-mini | 19.8% | 51.8% | 92.4% |
| claude-3-5-sonnet | 78.1% | 93.8% | 94.4% |
| llama-3.17b | - | 60.9% | 76.8% |
What is SAP and why does it work so well?
The key idea behind SAP is to assume that the model will make mistakes, and to build a parser that is robust enough to handle them. This would be virtually impossible for some tasks, but in the context of structured data extraction, we have a schema to guide us. A key inspiration to us was Postel's Law, coined by Jon Postel, the creator of TCP/IP:
Be conservative in what you do, be liberal in what you accept from others.
We'll do a future post that outlines exactly how our SAP algorithm works. At a very high-level, you can think of the leetcode problem "Edit Distance" but instead of comparing two strings, we ask: "What is least cost edit I need to make to get from the model's output to something parseable by a schema?" The simplest cost function could be Levenshtein distance, but we use a custom cost function that takes into account the schema. (The code is open-source, so you can check it out here)
Meanwhile, here are three examples to show some of the error correction techniques we use:



- Included a comment
- Used a fraction instead of a float
- Forgot quotes around
stands_for - Didn't escape the newline or
"within the string - Included a trailing comma



"Amazon"was returned as astring, butFounder.prior_jobsshould be astring[]


- Included a lot of prefix and suffix text that is not relevant to our desired output, but may be relevant to the LLM to generate the output
Some more error correction techniques we use in SAP include:
- Unquoted strings
- Unescaped quotes and new lines in strings
- Missing commas
- Missing colons
- Missing brackets
- Misnamed keys
- Cast fractions to floats
- Remove superfluous keys in objects
- Strip yapping
- Picking the best of many possible candidates in case LLM produces multiple outputs
- Complete partial objects (due to streaming)
- and more
Using SAP today
We wanted to offer SAP in all languages of your choice, so we've written it in Rust and provide a native interface for Python, Typescript, and Ruby. (We're working on more languages, but we're a small team!)
Since all interfaces use the same Rust code, you can expect the same performance and accuracy across all languages.
You can try it on our online playground: https://promptfiddle.com or add it to your code base already. (Go to documentation)
Code Snippet
- Write a schema in BAML
// my_app/baml_src/my_schema.baml
class Resume {
name string @description("first and last name")
email string?
experience Experience[]
}
class Experience {
title string
company string
}
- Write an LLM prompt in BAML
// my_app/baml_src/my_schema.baml
// ...
function ExtractResume(text: string) -> Resume {
client "openai/gpt-4o"
prompt #"
Describe this resume.
{{ ctx.output_format }}
{{ _.role('user') }}
{{ text }}
"#
}
- Create bindings in your language of choice and use the BAML defined function as if it were a native function (with autocomplete and types!).
Python
$ pip install baml-py
$ baml-cli generate --from /path/to/my_schema.baml --target "python/pydantic"
from baml_client import b
# resume will always be a Pydantic model of type Resume
resume = b.ExtractResume("""
Vaibhav Gupta
vbv@boundaryml.com
- Founder @ BoundaryML
""")
# BAML will automatically validate the response via SAP and cast it to a Pydantic model
Typescript
$ npm install @boundaryml/baml
$ ./node_modules/.bin/baml-cli generate --from /path/to/my_schema.baml --target "typescript"
import { b } from './baml_client'
// resume will always be a TypeScript interface of type Resume
const resume = await b.ExtractResume(`
Vaibhav Gupta
vbv@boundaryml.com
- Founder @ BoundaryML
`);
// BAML will automatically validate the response via SAP and cast it to a TypeScript interface
Ruby
$ gem install baml
$ baml-cli generate --from /path/to/my_schema.baml --target "ruby/sorbet"
require 'baml_client'
# resume will always be a Sorbet model of type Resume
resume = b.ExtractResume(<<~TEXT)
Vaibhav Gupta
vbv@boundaryml.com
- Founder @ BoundaryML
TEXT
# BAML will automatically validate the response via SAP and cast it to a Sorbet model
Does this really matter since models will get better?
I think one could make an arguement for no. If models get better, then JSON mode will be sufficient.
But I personally think performance always matters. If I had some technique that can get the same quality 50% faster or 50% cheaper, then I would obviously use it. Besides, as models get better, I would much rather they spend their training data on being better at understanding the world, rather than understanding my schema. The schema part we can solve with engineering.
Mandatory Blurb 🤝
Our mission at Boundary is to provide the best possible developer experience for shipping AI pipelines. We started with BAML, our new programming language for providing a boundary between stochastic AI models, and deterministic, type-safe code.
What's next? Likely we'll be showing off demos of how to combine function calling and structured generation with SAP to get the best of both worlds. Stay tuned!
If you enjoyed this article, please consider giving us a star on GitHub.